PowerShellで配列内のユニークな値の数を数える

そこそこ大量のCSVデータを処理するスクリプトをPowerShellで書いていたのですが、データ量が増えるにつれて妙に遅くなってしまいました。 Write-Progressとか入れながら調べてみたところ、重複を省いたユニークな個数を数える所で遅くなっていたようです。
やっている作業のイメージ
入力値として、以下のような雰囲気のテーブルがあります。
| 名前 | 教科 | 点数 |
|---|---|---|
| Charlie | 国語 | 90 |
| Alice | 国語 | 80 |
| Bob | 数学 | 70 |
| Alice | 数学 | 90 |
このテーブルから、合計何人の人が居るかを知りたいというのが今回やりたいタスクになります。 上記の例だと「3名」って出ればOKということですね。
別にテーブルである必要性は無いので、配列でOKです。 というかこれ以降は配列として話を進めます。
結果
まずはベンチマーク結果から。 実行環境や使ったコードは末尾に記載してあります。
なお、単位はすべて秒です。
100種類の数字を100万個
0から99までのランダムな数字が100万個入った配列から、何種類の数字が入っているかを数えさせた場合の結果です。
| 方法 | 1回目 | 2回目 | 3回目 | 平均 |
|---|---|---|---|---|
| Sort-Object -Uniq | 289.99 | 289.68 | 289.06 | 289.58 |
| Sort-Object + Get-Unique | 13.44 | 13.65 | 12.56 | 13.22 |
| Select-Object -Uniq | 11.33 | 11.13 | 11.01 | 11.16 |
| hashtable + foreach | 0.91 | 0.90 | 0.88 | 0.90 |
| HashSet + foreach | 0.91 | 0.88 | 0.88 | 0.89 |
| HashSet + switch | 0.46 | 0.45 | 0.44 | 0.45 |
| hashtable + switch | 0.46 | 0.43 | 0.43 | 0.44 |
| HashSet::new | 0.19 | 0.18 | 0.20 | 0.19 |
| HashSet.UnionWith | 0.19 | 0.19 | 0.18 | 0.19 |
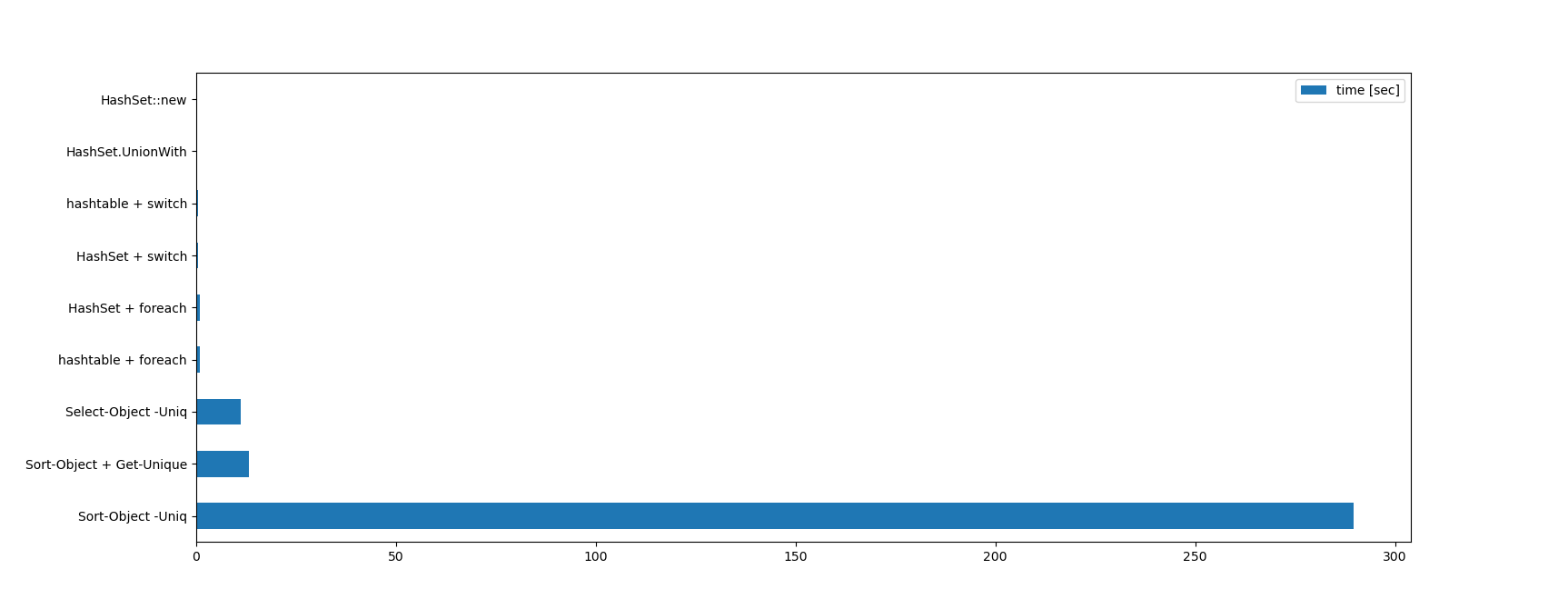
一応グラフにしましたが、差が激しすぎて最速のhashtable::newやhashtable.UnionWithなどは最早見えません。 Sort-Object -Uniqが遅すぎる…。
1万種類の数字を100万個
特性によって違うと思うので、別パターン。 こちらは1万種類のランダムな数字が100万個入った配列を使いました。
最初は10万種類100万個で試そうとしたのですが、あまりにも遅いので諦めました。 Select-Objectを使った方法は値の種類が増えた場合に極端に弱いようです。
| 方法 | 1回目 | 2回目 | 3回目 | 平均 |
|---|---|---|---|---|
| Select-Object -Uniq | 1114.27 | 955.25 | 865.42 | 978.31 |
| Sort-Object -Uniq | 456.47 | 308.69 | 285.30 | 350.15 |
| Sort-Object + Get-Unique | 14.07 | 14.05 | 13.70 | 13.94 |
| hashtable + foreach | 1.12 | 1.15 | 1.14 | 1.14 |
| HashSet + foreach | 0.91 | 0.91 | 0.92 | 0.91 |
| hashtable + switch | 0.53 | 0.55 | 0.75 | 0.61 |
| HashSet + switch | 0.45 | 0.45 | 0.45 | 0.45 |
| HashSet::new | 0.20 | 0.19 | 0.20 | 0.20 |
| HashSet.UnionWith | 0.20 | 0.19 | 0.19 | 0.19 |
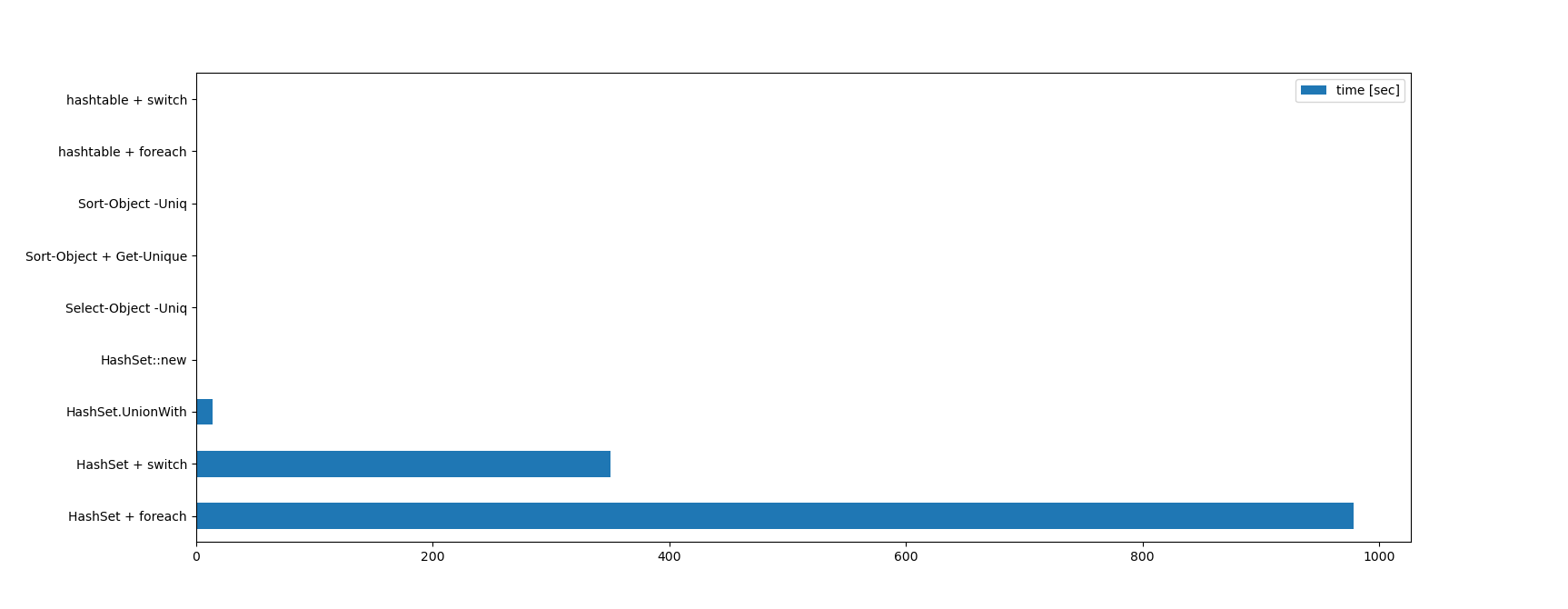
さらに差が激しくなっていて、もうグラフとして成立してない気がしないでもないです。
HashSet、hashtableのハッシュを使った系の速さと種類による影響の無さがよく分かりますね。
試してみた方法
Select-Object -Uniq
おそらく最も簡単な方法です。 私が書いた遅いスクリプトで使っていた方法でもあります。
やりたい事をストレートに実装しているコマンドレットなので良い感じにやってくれるかと思いきや、出現する値の種類が増えた場合に極端に遅くなってしまいました。
Select-Objectの実装を覗いてみたところ、今までに出現した値を全部リストに保持しておいてチェックするO(n^2)な二重ループ構造になっているようです。
そりゃ遅いわけだ。
使い方は以下のような感じ。
($TargetArray | Select-Object -Uniq).Count
Sort-Objectを使う方法と比べると、以下のような感じで結果がソートされないのがポイントですね。
> @("Charlie", "Alice", "Bob", "Alice") | Select-Object -Uniq Charlie Alice Bob
Sort-Object -Uniq
出現する種類が少ない場合の断トツのワースト1位。 一方で種類が多くした場合でもあまり速度が変わっていないので、種類に影響されず全体の個数に影響されるような雰囲気があります。
コードは以下のような感じ。
($TargetArray | Sort-Object -Uniq).Count
Sortなので当然ですが、結果は以下のようにソートされています。
> @("Charlie", "Alice", "Bob", "Alice") | Sort-Object -Uniq Alice Bob Charlie
Sort-Objectの実装を軽く読んでみたのですが、ソートした後で重複している部分を詰める的な動作をしているっぽいです? 案外結構複雑な挙動になっていました。
Sort-Object + Get-Unique
試す前はこれが1番遅いかと思っていたのですが、残念ながら(?)ワースト1位にはなれませんでした。意外と速い。
特に種類が多い場合の善戦っぷりが凄いです。 重複を排除する段階では一個前と比較するだけなので、種類の多さに影響されないのは当然と言えば当然ですね。 といっても遅いは遅いのですが…。
コードは以下のようになります。
($TargetArray | Sort-Object | Get-Unique).Count
Sort-Object -Uniqのコードを2段階に分割したような構成になっています。 分割された分だけ遅いと思ったんですけどね…。
ちなみに、Get-Uniqueは以下のような挙動をします。
> @("Alice", "Alice", "Bob", "Alice") | Get-Unique Alice Bob Alice
単純に連続した要素を捨てるやつですね。
HashSet + foreach
やる前はかなり速かろうと思っていた方法です。 実際やってみたら、HashSetの代わりにhashtableを使った方法と大体同じくらいでした。 値の種類の量によって若干差が出ていますが、ほぼ誤差な気がします。
コードは以下になります。
$hashset = [System.Collections.Generic.HashSet[int]]::new() foreach ($x in $TargetArray) { $hahset.Add($x) } $hashset.Count
switchを使った方法はもっと速いのですが可読性が皆無なので、わりと現実的な選択肢です。
最初から全部の値が手に入る場合はHashSet::newを使った方法で、そうでないならばこちらを使った方法、という使い分けになるでしょうか。
hashtable + foreach
JavaScriptとかでやりがちな、連想配列を集合型の代わりに使う方法です。 見た目がそんなに速そうに見えないのですが、実はHashSetを使った方法に匹敵するスピードが出ました。
$table = [hashtable]@{} foreach ($x in $TargetArray) { $table[$x] = $true # キーだけが重要なので、中身は何でも良い } $table.Count
コメントも入れましたが、若干コードの意味が分かりづらくなるように思います。 可読性という点ではHashSetを使った方法に軍配が上がるでしょうか。 System.Collections...を書かなくて良いのは嬉しいのですけれどね。
HashSet + switch
HashSetとforeachを使った方法やhashtableとforeachを使った方法をもっと速く出来ないかと考えて、ループ部分の最適化にも挑戦してみました。というのがこの方法です。
この方法は、PowerShellで最速のループはswitchだという衝撃的な記事に基づいています。 そして実際速かった。すごい。
コードは以下のようなものになりました。
$hashset = [System.Collections.Generic.HashSet[int]]::new() select ($TargetArray) { default { $hashset.Add($_) } } $hashset.Count
完全にハックって感じです。 知らないと読めません。
プロダクションコードでは使っちゃいけない気がしますが、foreachを使う方法の倍近く速いです。 書き捨てでとにかく速さが欲しい時用でしょうか…。
hashtable + switch
こちらもHashSetとswitchを組み合わせた方法と同じく、switch文を悪用…じゃなくて活用した高速化バージョンです。
値の種類が多い場合、少ない場合のどちらでも同率1位という感じの成績でした。
コードは以下です。
$table = [hashset]@{} switch ($TargetArray) { default { $table[$x] = $true } } $table.Count
やはりswitchを使った方法はハックという感じが凄いですね…。
HashSet::new
本命の最速候補です。 HashSetの作成と同時に配列の中身を全部入れる方法です。
[System.Collections.Generic.HashSet[int]]::new([int[]]$TargetArray).Count
型情報だらけになので若干不思議な見た目ですが、中身はHashSetを作って数えるだけなので非常にセマンティックな感じです。
処理がほぼ全部.NET内で完結するだけあって、非常に速いです。
HashSet.UnionWith
本命の亜種。
初期化時には値を入れないで、後からUnionWithで追加してみたパターンです。
$hashset = [System.Collections.Generic.HashSet[int]]::new() $hashset.UnionWith([int[]]$TargetArray)) $hashset.Count
初期化時から値を投入した場合ともほぼ速度が変わらないので、用途次第で使い分けられそうです。
実行環境
上記のベンチマークは以下の環境で実行しました。
> $PSVersionTable Name Value ---- ----- PSVersion 5.1.18362.145 PSEdition Desktop PSCompatibleVersions {1.0, 2.0, 3.0, 4.0...} BuildVersion 10.0.18362.145 CLRVersion 4.0.30319.42000 WSManStackVersion 3.0 PSRemotingProtocolVersion 2.3 SerializationVersion 1.1.0.1
ベンチマークで使ったコード
ベンチマークのコードは以下になります。 コピペでそのまま動くはず。
$ns = 1..1000000 | foreach { (get-random) % 100 } # 100種類が100万個 #$ns = 1..1000000 | foreach { (get-random) % 10000 } # 1万種類が100万個 Write-Host "Select-Object -Uniq:" (Measure-Command { ($ns | Select-Object -Uniq).Count }).TotalSeconds Write-Host "Sort-Object -Uniq:" (Measure-Command { ($ns | Sort-Object -Uniq).Count }).TotalSeconds Write-Host "Sort-Object + Get-Unique:" (Measure-Command { ($ns | Sort-Object | Get-Unique).Count }).TotalSeconds Write-Host "HashSet + foreach:" (Measure-Command { $hashset = [System.Collections.Generic.HashSet[int]]::new() foreach ($x in $ns) { $hashset.Add($x) } $hashset.Count }).TotalSeconds Write-Host "hashtable + foreach:" (Measure-Command { $table = [hashtable]@{} foreach ($x in $ns) { $table[$x] = $true } $table.Count }).TotalSeconds Write-Host "HashSet + switch:" (Measure-Command { $hashset = [System.Collections.Generic.HashSet[int]]::new() switch ($ns) { default { $hashset.Add($_) } } $hashset.Count }).TotalSeconds Write-Host "hashtable + switch:" (Measure-Command { $table = [hashtable]@{} switch ($ns) { default { $table[$_] = $true } } $table.Count }).TotalSeconds Write-Host "HashSet::new:" (Measure-Command { [System.Collections.Generic.HashSet[int]]::new([int[]]$ns).Count }).TotalSeconds Write-Host "HashSet.UnionWith:" (Measure-Command { $hashset = [System.Collections.Generic.HashSet[int]]::new() $hashset.UnionWith([int[]]$ns) $hashset.Count }).TotalSeconds
2020-11-05 追記
Twitterで頂いた情報を元に、HashSet::newを使った方法とHashSet.UnionWithを使った方法を追加して内容を更新しました。 案の定最速だった上に見た目も見やすいので、積極的に使っていけそうです。